Printed from acutecaretesting.org
January 2010
Interpretation of laboratory results



Introduction
In hospital settings, from year to year, an ever increasing amount of laboratory tests are ordered and this expansion seems not to have reached its upper limit yet. Considering the high volume of laboratory tests it seems that the values of the tests are more and more evident to the clinicians and patient care. Even more important is the high level of confidence the clinicians place on laboratory data.The selection of the diagnostic laboratory parameters depends greatly on the medical problem in question, but in the lab we often see many different tests ordered on each single sample. Ordering too many tests in an uncritical manner will not necessarily provide the clinician with more information, and it can sometimes make it even more difficult to interpret the results.
Therefore, when selecting a test it is important that the clinician knows how appropriate the test is for its intended use and not least to know how reliable the test result is. In this respect it is an important task for the laboratory to provide the necessary information about methods and test results, thereby supporting the clinician in the decision-making process.
A rational use of clinical biochemical analysis requires an understanding of what laboratory results actually include. Therefore it is important to understand the following concepts:
- Reference interval
- Bias (accuracy)
- Precision
- Sensitivity
- Specificity
- Predictive value
Reference interval
Interpretation of a laboratory result requires that the result can be related to a relevant reference value. This can be the same patient’s earlier results, if this is possible, or be done by comparing to data from a "normal" population. In the latter case, to make use of the test result a reference area for the analysis in question must be specified.
A reference area is established by collecting sample material from a normal healthy population, at least 100 persons, preferably several hundred persons. That could be the laboratory’s own investigations based on samples from blood donors or for instance from hospital staff or by using data from literature. To establish a well-defined reference interval IFCC protocols are available [1].
Measurement of samples from different individuals will, as you would expect, not give exactly similar results. This is because of the natural biological variation and the uncertainty of the measurement itself. A reference interval based on a normal population will thus cluster around the mean and often show a normal distribution or Gaussian distribution. The form of the distribution depends on the biological variation for the analyte in question, the sampling and treatment of the material and on the measurement uncertainty.
To use this reference distribution clinically you need to limit the area by introducing a reference interval. If the variable measured has a normal distribution, statistically approximately 95 % (95.6 %) of the values will be within the range given by mean ± 2 standard deviations. The measurements within these limits are often used to describe the test values typically observed in a healthy population and are often referred to as the "normal range". Likewise, approximately 99 % will be within mean ± 3 standard deviations.
Thus, a reference interval including 95 % of the values is limited by a lower and upper reference limit, corresponding to respectively 2.5 % and 97.5 %. The values on both sides of these reference limits are thus not included in the "normal range". Statistically, this means that 5 % in a population or one out of twenty must be considered as being abnormal!
If two tests are ordered, the probability of the second test being within the normal population is also 95 %, but the probability that both test are normal is 0.952 = 0.90. If 10 tests are ordered, which often occur, the probability that all are within the 95 % interval is 0.60. On the other hand, some biochemical parameters show considerable biological variation so it is also possible for a patient with a pathological condition to have a test result within the reference interval (Fig. 1).
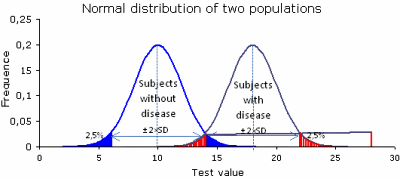
Fig. 1: Normal distributions, with mean = 10 and mean = 18, standard deviation = 2. 95% of the values are within ± 2×SD.
In that way abnormal results do not always indicate a disease or a pathological situation, nor does a normal result always indicate the absence of a disease. Of course the more abnormal the result is, the greater the probability that the result is related to a pathological condition.
When establishing a reference interval, several biochemical parameters will not show a normal distribution. So-called skewed distributions are frequently found, but the data can often be transformed to a normal distribution by applying logarithmic transformation. Without transformation about 95 % of the observations will still fall within the 2 standard deviation limits, but those 5 % outside may well be at one end.
To avoid this non-parametric statistics can be used to define the 2.5th and 97.5th percentiles, or more simply you may have to define the reference limits so that 2.5 % of the results is cut from each side of the distribution. For some parameters it has been decided to use the 99th percentile so that 1 % of the results is cut in the upper range.
The interval may often differ, depending on age, sex, size or ethnic background and it is therefore a labor-intensive and a costly affair to collect data from vast numbers of laboratory tests to establish a reference interval. For many commercial analytical methods the manufacturer establishes the reference interval. To make use of this, it must be stressed that the interval has to be well defined and suitable for the demographic population.
In recent years, major projects, involving several laboratories from different countries, have participated in collecting and measuring samples with the purpose of establishing common reference intervals. In that way reference intervals for the most common analytes have been established on the basis of a large number of data, e.g. the Nordic Reference Interval Project (NORIP).
|
Reference interval |
Children: |
0-1 week |
53-97 µmol/L |
Establishment of a reference interval thus allows the clinician to compare results from an individual with results from a population and hereby take advantage of the fact that intra-individual biological variation, even though it can be considerable, is much less than the variation for the population in question.
Intra-individual biological variation
Even though an individual may differ significantly from a normal population, it is nevertheless important to consider the intra-individual variation for the biochemical parameter in question. Many analytes are measured with higher or lower result, dependent on fluctuation of body fluid constituents around a homeostatic set point. In this fashion, seasonal variation, biological cycles or rhythms, food intake, exercise or just the time of the day can affect the parameter to be measured.This is of course of particular interest when comparing a patient’s test results with a previous one, e.g. in connection with evaluation of a treatment. When doing this, the clinician must take the biological variation into account and perform a critical evaluation of the alterations observed in the results.
There is not always a clear dividing line between health and disease, but nevertheless a tendency to interpret laboratory test as either health or a disease. So in using reference interval limits there will be some instances that will cause unnecessary false alarm.
As an example, during a development of a disease, in the first stages or in the progression, the biological variation is a potential risk of false interpretation. Likewise, for some quantities the biological variation in pathological states is higher than in the healthy state and the diagnostic value of the test is reduced.
The biological variation can be estimated on the basis of measured values for analytical variation (CV):
CVbiological =
The biological variation for a biochemical parameter is a measure of how large an increase/decrease can be expected to contribute to the analytical variation in a normal situation.
The factor 2.77 is equal to ![]() times the z statistic for the difference, which is 1.96 for this example with a probability of 0.05 (5 %) that the result is due to random variation. The z score depends solely on the probability selected for significance and on whether the changes are uni-directional (rise OR fall) or bi-directional. Examples of z values can be found in Fraser [2].
times the z statistic for the difference, which is 1.96 for this example with a probability of 0.05 (5 %) that the result is due to random variation. The z score depends solely on the probability selected for significance and on whether the changes are uni-directional (rise OR fall) or bi-directional. Examples of z values can be found in Fraser [2].
Knowledge of the intra-individual biological variation is thus of absolute relevance for the evaluation of a laboratory result.
Glucose is measured both in plasma and as whole-blood glucose. The intra-individual biological variation for glucose is CVbiological ~6 %, while the analytical variation is CVanalytical ~2 % for plasma glucose and 3-4 % for whole blood. The patient’s day-to-day variation will then be:
6.3 % for plasma glucose
Now calculating the critical difference CD = 2.77 * ![]() = 18 % implies that two glucose test values that diverge more than 18 % will be significantly different.
= 18 % implies that two glucose test values that diverge more than 18 % will be significantly different.
- FPG < 5.6 mmol/L ~ normal
- 7.0 mmol/L > FPG ≥ 5.6 mmol/L ~ IGT
- FPG ≥ 7.0 mmol/L ~ diabetes.
When comparing test results with the recommended limits, the biological and analytical errors must be considered.
Accuracy and precision
When a sample is measured several times, it is rare to get the same results every time. Instead the results will deviate more or less depending on the precision of the measurement method. Likewise, measuring a sample by two different methods will seldom give exactly the same results, but differ more or less depending on the accuracy of the methods.
Thus the two major contributions to analytical uncertainty are precision (imprecision) and accuracy (bias), each contributing with random errors and systematic errors. Precision is defined as the degree to which replicate measurements under unchanged conditions show the same results. In the laboratory the term imprecision is more often used as the random analytical errors affecting the results.
Accuracy is defined as the degree of closeness of measurements of a quantity to its actual or accepted value. It is, however, more often the term bias, which equals the amount of inaccuracy, that is used in the laboratory to describe the systematic differences between measurement methods or between a method and a reference value.
When determining precision, it is important to use analyte concentrations close to clinical decision limits. For each concentration a mean (M) and a standard deviation (SD) is calculated:
SD = ![]()
The standard deviation or the so-called coefficient of variation (CV), which is the SD in percent of the mean, is a measure of the precision:
CV = ![]()
The SD then represents the sum of all variations affecting the analysis. This is, for example, the test instrument, different technologists handling the analysis, environmental conditions and simply day-to-day variations. The SD is then a measure of the interserial precision.
When determining bias, the mean of a series of measurements on a sample is compared to a known concentration of the analyte in the sample, or to an expected value. The magnitude of the bias could be determined by use of a relevant reference material (e.g. certified reference material) containing a known concentration of the analyte.
In the clinical chemistry laboratory a method bias is usually determined by comparison of results with results from a number of other laboratories measuring the same sample material. This interlaboratory comparison, known as proficiency testing, implies that the laboratory receive samples with an unknown concentration of an analyte with regular intervals.
Usually the comparison is done with laboratories using the same methodology and the comparison then shows the ability of a laboratory to achieve a correct test result. As stated, bias is caused by systematic errors such as calibration, changing reagent (lot no.), etc. and corresponding to imprecision, the SD or CV in relation to the reference value or interlaboratory comparison is a measure of the method bias. These error types are independent in the sense that you can have an analysis with a high precision, but with a low accuracy and vice versa.
Normally in the lab when two or more instruments are used for the same analysis, a regular method comparison and bias check are conducted by parallel analysis. Equipment used in point-of-care testing (POCT) is a good example with quite a lot of instruments all over the hospital. In this way it should make no difference for the patient result whether the sample has been analyzed on instrument #1, instrument #2, #3 or #10.
Frequently precision and bias are illustrated with shooting at a bulls-eye. The deviation from the center equals bias, whereas precision corresponds to the spreading of the bullet holes.
The analytical variation can contribute considerably to the reliability of a laboratory test, in particular when the biological variation is low compared to the analytical error. When interpreting a test result, it must be possible for the clinician to know the bias and the method's precision or the total error (TE) for the method:
TE = B + 1.96 * I
B = bias, I = imprecision, level of significance 95 %). This could be on an accompanying or readily available method or a datasheet (in the laboratory information system or on the web). For many laboratory tests, external quality assessment programs or government regulations (e.g. CLIA) provide values for acceptable analytical variation, so-called total allowable errors (TEa), that includes the imprecision and bias of a measurement.
Please note that bias as a systematic difference between a test and a reference (true) value is not relevant for a test that is not standardized; an example could be the D-dimer test.
As an example of the importance of analytical error is measurement of C-reactive protein (CRP) as an acute-phase reactant, and as a test for risk of cardiovascular diseases. As an acute-phase reactant CRP can increase dramatically in response to, e.g. infections, and the test measures a broader range of CRP levels.
Because of a high imprecision in the lower ranges the method will not be sufficient as a test for risk of cardiovascular diseases. For the prediction of cardiovascular disease the analysis must be able to discriminate between CRP values of:
- < 1.0 mg/L (low risk)
- > 1.0mg/L and < 3.0 mg/L (average risk)
- > 3.0 mg/L (high risk)
(American Heart Association and US Centers for Disease Control and Prevention). The precision performance of the analytical method is certainly very important. However, several high-sensitive CRP assays show analytical imprecision in the range of 5-10 %, and this will probably not be adequate. According to Westgard [3] the allowable CV should really be around zero.
Sensivity and specificity
In clinical biochemistry terminology a sensitive method usually means that the analysis is able to measure low concentrations of the analyte, and specificity means the method's ability to measure the analyte itself, without interference from other substances in the testing sample. Thus the terminology here refers to the analytical sensitivity and the analytical specificity.When laboratory tests are interpreted, we talk about the clinical or diagnostic sensitivity and specificity that deal with the possibility of whether a patient has a disease or not. For the clinician the diagnostic sensitivity and specificity are important issues that reveal how reliable a test is and how suitable it is for the intended purpose.
When a laboratory result shows a value corresponding to a particular disease condition, there are two possibilities: the disease can be present or the disease can be absent. In the first case we are dealing with a true positive (TP) result and in the latter with a false positive (FP) result for the disease. Similarly, if the result shows the absence of a disease, the person may be free from the disease or actually have the disease. In this case we have true negatives (TN) or false negatives (FN), respectively.
Diagnostic sensitivity is a measure of the proportion of actual positives that are correctly identified as positive. It is then a measure of the ability of the analytical method to identify a particular disease condition. Sensitivity is calculated as the percentage of true positives (TP) among everyone with the disease (Fig. 2):
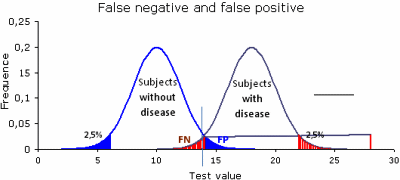
Fig. 2: Normal distributions, with mean = 10 and mean = 18, standard deviation = 2. 95% of the values are within ± 2×SD.
For a cutoff at 95% red = False negative, blue = false positive
TP / (TP + FN)
In the same way, diagnostic specificity measures the proportion of negatives that are correctly identified and is thus a measure of the method's ability to exclude a particular disease. Specificity is then calculated as the percentage of true negatives (TN) among everyone without the disease:
TN / (TN + FP)
A test showing that a woman is not pregnant, when she actually is, is an example of a test of low sensitivity, whereas low specificity is a test showing pregnancy when the woman is not pregnant.
Even though a test method has a high specificity and a high sensitivity you will not necessarily get the correct answer to make a diagnosis. This depends to a large degree on the prevalence of the disease; that is the number of persons with a disease in a given population, especially when the prevalence is low.
For instance, a very rare disease and a laboratory test for that disease with a sensitivity and specificity less than 100 %. The probability of false positive results is high and thereby a low predictive value is obtained.
The predictive value is the probability that the disease is present when the test result is positive or that the disease is absent when the test result is negative. In a formula, this can be shown like this:
Predictive value of a positive test result: PPV = TP / (TP + FP)
Predictive value of a negative test result: NPV = TN / (TN + FN)
The predictive values thus depend on the sensitivity, specificity and prevalence and thereby represent the probability that a positive test reflects the underlying condition being tested for.
Conclusion
Several parameters are important when a laboratory result is interpreted, and further, the interpretation also depends on the reason for which the test is requested - whether it is for a diagnostic purpose or for monitoring or for screening. If the test is requested for exclusion of a diagnosis, then a highly sensitive test is required; if it is for diagnosis of a high-risk disease, then a highly specific parameter is needed.Interpretation of a laboratory result actually starts with the clinician requesting the right test for the clinical problem he/she is facing. The expectation is that the result will provide information that will support decision on the subsequent treatment. What actions are taken depends on the clinician's understanding of the laboratory result and how to respond to the information. This circle from considering a laboratory analysis to interpretation and to action is the brain-to-brain cycle [4].
- Preanalytical parameters
- Biochemical test
- Biological variation
- Appropriate time when to have the appropriate samples taken
- Analytical parameters
- Accuracy
- Imprecision
- Diagnostic sensitivity and specificity
- Postanalytical parameters
- Clinical decision limits
- Failure rates
- Clinical interpretation
Many studies have focused on errors in the preanalytical and analytical phases, but fewer on the postanalytical errors. A high error rate in sample collection, identification and barcoding, analysis and reporting would be presumed, but these errors seem to be less frequent compared to errors in selecting the right test and errors in interpretation of the result. According to Laposata [5] a survey has shown that for a coagulation disorder, approximately 75 % of the cases would have involved some level of test result misinterpretation.
According to literature 70-80 % of decisions in diagnosis are based on laboratory outputs. In the laboratory a lot is done to assist in the interpretation of results, besides reference values, measurement error, flagged results and so on.
However, there is obviously still a lot to do regarding better reporting of data - and information; information that could support medical personnel in applying laboratory information appropriately. Web-based laboratory information systems could be improved with decision aids and tools that take into account the evidence-based knowledge.
References+ View more
- Defining, Establishing and Verifying Reference Intervals in the Clinical Laboratory; Approved Guideline – Third edition. C28-A3, Vol. 28 no.30www.clsi.org/source/orders/free/c28-a3.pdf.
- Fraser CG, Petersen PH, Larsen LM. Setting analytical goals for random analytical error in specific clinical monitoring situations. Clin Chem 1990; 36(9): 1625-28
- Quintiles and quality: QC for HS-CRP www.westgard.com/quest15.htm
- Goldschmidt HMJ. The NEXUS vision: an alternative to the reference value concept Clin Chem Lab Med 2004; 42(7): 868–73
- Laposata M. Dighe A: "Pre-pre" and "post-post" analytical error: high-incidence patient safety hazards involving the clinical laboratory. Clin Chem Lab Med 2007; 45(6): 712–19 www.reference-global.com/doi/abs/10.1515/CCLM.2007.173
References
- Defining, Establishing and Verifying Reference Intervals in the Clinical Laboratory; Approved Guideline – Third edition. C28-A3, Vol. 28 no.30www.clsi.org/source/orders/free/c28-a3.pdf.
- Fraser CG, Petersen PH, Larsen LM. Setting analytical goals for random analytical error in specific clinical monitoring situations. Clin Chem 1990; 36(9): 1625-28
- Quintiles and quality: QC for HS-CRP www.westgard.com/quest15.htm
- Goldschmidt HMJ. The NEXUS vision: an alternative to the reference value concept Clin Chem Lab Med 2004; 42(7): 868–73
- Laposata M. Dighe A: "Pre-pre" and "post-post" analytical error: high-incidence patient safety hazards involving the clinical laboratory. Clin Chem Lab Med 2007; 45(6): 712–19 www.reference-global.com/doi/abs/10.1515/CCLM.2007.173
May contain information that is not supported by performance and intended use claims of Radiometer's products. See also Legal info.


Acute care testing handbook
Get the acute care testing handbook
Your practical guide to critical parameters in acute care testing.
Download now
Scientific webinars
Check out the list of webinars
Radiometer and acutecaretesting.org present free educational webinars on topics surrounding acute care testing presented by international experts.
Go to webinars